
I have been working on a web-like browser for the MEGA65 on and off for a while. The idea is to make something that works and feels like a web-browser, but uses a special page format that is much easier for a little computer like the MEGA65 to parse. This format allows text, images and hyper-links, and will in the future allow simple forms and buttons, to make something that allows for some degree of interaction.
To make this, we are using the MEGA65's Ethernet controller. This really is a stress-test for the ethernet controller in a lot of ways, and is helping me to shake out any remaining bugs that it has, and to generally improve its performance.
We also need a working TCP/IP stack. I had already ported the small and simple WeeIP to the MEGA65, and continue to extend and improve it as part of this project. For example, it didn't include DHCP support previously, nor TCP out-of-order segment reception.
Debugging both of these, and their interaction with modern TCP/IP stacks has been "interesting". That is, I am trying to debug the interaction of 3 components, 2 of which are known to need some work, and the 3rd of which has quite deep complexity that is very hard to expose.
So let's start with the ethernet controller. I knew it had some funny problems with the buffer rotation which needed fixing. Basically it would often present the 2nd-last receive frame instead of the most recent one, and things like that.
It turned out to be a combination of things, which I was able to tease out by making a loop-back plug for the ethernet jack, so that I could control the injection and monitoring of the ethernet connection. This is as simple as chopping the head off of an ethernet cable, and soldering the correct wires together.
To solve the problems that this uncovered, I overhauled the whole RX buffer management to make it much simpler. Now the IRQ gets asserted whenever there are any frames received. The CPU can see the current RX buffer, which will have a received frame in it when the IRQ gets asserted. The CPU then releases that buffer by writing the appropriate value to $D6E1, which tells the ethernet controller to advance which buffer the CPU can see, and to free up the buffer the CPU was previously looking at.
The result is that the ethernet controller now reliably delivers frames as soon as they are received, and doesn't get all confused about which RX buffers are free and which are occupied.
So that signficantly reduces the complexity of the remaining problem to the TCP/IP stack interactions.
WeeIP originally only supported in-order TCP reception, and with a window size of one segment. It also didn't negotiate to increase the maximum segment size, so the default of 576 bytes was used, which increases the number of packets required for a transfer, which with the one-segment window was a recipe for really horrible performance.
I have since added out-of-order reception, to allow for one "island" of data to be tracked that is separated from the part of the stream that has been acknowledged. It's not perfect, but its a reasonable trade-off in terms of the added memory and code complexity to implement, and it solves the problem of bad performance when a single frame is dropped.
This is important, because the TCP fast-start scheme used by modern TCP/IP stacks gets a bit confused by the performance characteristics of the MEGA65 and its Ethernet interface: It's a 100mbit ethernet interface, and so has fundamentally very low latency. This means that the MEGA65 can respond to TCP packets sometimes in as little as 2 - 3 ms. "Big" computer's TCP/IP stacks interpret this as permission to open the fire-hose wide, and start sending lots of packets in quick succession, so that the data-rate climbs quickly.
The problem here is that the MEGA65 has only 4 Ethernet RX buffers, and WeeIP running in CC65-compiled C is not the most performant TCP/IP stack you could imagine. As a result, while the compiled C code is busy arranging its deck-chairs from the last packet, the next ice-berg of packets are arriving and slamming into it. As there are only 4 RX buffer slots, this means that packets get dropped.
TCP/IP is a bit prone to interpreting packet loss as congestion, but has made good improvements in this behaviour in recent years. As a result, modern TCP/IP stacks try to measure the round-trip time of packets and do all sorts of interesting things to figure out the best rate to send packets. Unfortunately, they weren't really designed with the MEGA65's characteristics in mind. It seems that for Linux at least, the TCP/IP stack decides that what it is seeing is heavy congestion, and slows right down, often to one packet every few seconds. But the real problem is that I can't figure out a good way to see if that's actually what Linux is thinking or not.
Adding some out-of-order reception support helps this, because it allows us to keep data that has arrived immediately after a packet has been dropped, so that we only need to "fill in the gaps", rather than have it all be retransmitted. However, WeeIP doesn't seem to have a very stable ACK retransmission scheme, and so even with that, there can be long periods of time -- like seconds to tens of seconds -- when it doesn't send an ACK to remind the sender of where it is up to. It is more reactive, that is, it tends to ACK when it sees a packet arrive, rather than knowing that it should send an ACK if the link has been silent for a while. So I'll have to fix that.
It is important to fix those sorts of errors, because otherwise, even adding more RX buffers to the ethernet controller will not have much effect -- it will just allow the TCP/IP stack to get stuck faster. It's like driving in peak-our on the autobahn near Frankfurt: You can go 200km/hour all you like for a short stretch, but soon enough you will catch up with the 15km long column of stationary traffic, and at that point, you might as well get out of your car and have a picnic on the asphalt.
After quite a bit of rabbit-hole diving, I think I now have the TCP Selective ACK (SACK) adequately implemented, along with fixing a pile of other bugs.
Now we are back to the point where it looks like the TCP/IP stack is performing well, or more specifically, that problems with the Ethernet controller are causing more problems: I have found that there is still some corruption of received Ethernet frames happening fairly often. For some reason I had the CRC check disabled in the TCP/IP stack, which I have now re-enabled. This should hopefully fix random corruption bugs that I have been seeing. But I do need to also fix the underlying problem with the Ethernet controller.
My suspicion is that the Ethernet controller receive errors are due to poor synchronisation of the Ethernet RX lines with the ethernet clock line. I have done a bit of digging around, and found out how to impose some minimum and maximum delay constraints on that, which should hopefully help. That will require a re-synthesis run, which will take an hour or so.
In the meantime, I do have a register that allows me to partially control the RX phase via a POKE to change the upper 2 bits of $D6E5. However while I can make it worse, by setting the upper two bits to 11, it doesn't seem that any other value completely solves the problem. So it is possible that the two RX lines have different delays to one another, which is causing the problem. We'll see.
But even without that fix, with the Ethernet CRC check re-enabled, this should in theory mean that we get error free packets. The only visual problem we should get is that the TCP download of a page will take longer due to having to drop the corrupted packets.
But of course, I am not seeing that. So I need to probe again to see if any errors are sneaking past the Ethernet CRC check. I have an option I can enable in eth.c of the TCP/IP stack that saves all received Ethernet frames into an area of the Attic RAM, and a utility that can convert that saved memory into a pcap format packet capture that I can load into wireshark. This will let me see if there are still packets with errors coming through, or if they are being filtered out, which will in turn allow me to track down the source of the botched page loading.
That is revealing that errors are still sneaking through. It is possible, but unlikely, that those errors are actually errors reading or writing from the Attic RAM, as we have been seeing some niggly remaining problems with the controller for that as well. So I will need to find a way to exclude that possibility, as well.
The reason I am suspecting that, is that the CRC of an Ethernet frame should detect more than 99.9999% of all errors (see, e.g., https://paperhub.s3.amazonaws.com/8ff1e4414c070e900da8ab3885593085.pdf for an interesting exploration on the CRC32 used in ethernet, as well as other sources of error for packets on the internet).
So I really want to know for sure if the errors are happening on the Ethernet link or not. By modifying our little "wirekrill" native packet sniffer for the MEGA65, I have made it DMA all incoming ICMP ping packets onto the first line of an 80-column screen. This looks like rubbish, but part of the payload of a PING packet is constant: So I can watch for changes to that area.
Any, indeed bytes are being corrupted quite often. It also doesn't matter what phase I put between the Ethernet clock and the RX lines, it still happens.
The controller has a 2-bit wide interface from the Ethernet chip itself. I am suspecting that what happens is that bits arrive a bit early or a bit late sometimes, and so the position of a bit value varies. If this theory is correct, drawing the pattern of these dibits from the invariant section of a ping packet should show some tell-tale signs of bits being duplicated or shifted one time step.
Well, I have a nice utility that shows me 20 of those bytes, with each bit plotted, so that I can see how the problem looks in practice.
I'm seeing the kind of time-shift glitches, I expected. But I am also seeing some burstier noise, that tends to affect both bits at the same time. That might be real noise on the Ethernet line.
BUT there are two issues here:
1. The error rate for the bursty noise is way too frequent: Less than 1 in a million frames should have any errors, with cabling that meets the Cat 5 standard.
2. Both sorts of errors should be being rejected by the CRC check in the Ethernet controller, when it is enabled. Yet enabling this doesn't exclude more than about half of the errors.
So something very fishy is going on.
I wanted to be sure it wasn't the cable, so I set the same test up on loop-back, and I am seeing the same effects. So its not that.
Now I have modified that utility to show me when bits change between subsequent packets in these positions, and the results are interesting: They are not evenly distributed:

The top line is the raw bytes from the ping packets. The 2nd line is just references under the bytes to show where on the next section they are appearing: so the p with a 0 under it is plotted out in the four columns with 0's under them: Screen code for p is 0x10, and so we see this drawn out in the 2-bit high pattern with the four zero bits in the first two columns, and then bit 4 shown in the 3rd column.
Bellow all that is two more lines, where I increment the byte if the corresponding position in the bit display differs between two packets, i.e., an error has been observed. And you can see that some have been hit with many more errors than others.
Okay, so the errors are real. Now to think about how to get more detailed information on what is causing them, so that I can fix them.
The MEGA65's VHDL controller actually samples the RX lines at 4x the data rate. So I could modify it to log those over-sampled readings, so that I can see if the problem is glitching or drifting edges, or something else. Glitching would show up as single samples with the wrong value, while drifting edges would show as some bits being 3 or 5 ticks wide instead of always being 4.
I also want to read through the data sheet for the Ethernet PHY chip again, to make sure I am not doing something silly. There might, for example, be a separate receive clock line that I am not using, or something odd about the RX VALID signal that I have not taken into account.
So one thing I did just notice, is that I have not allowed for the RX VALID line to go low for a single tick, which it may need to do if there is clock drift between the Ethernet transmitter and receiver. This wouldn't fix the situation where I am seeing inverted bits, but is worth fixing, nonetheless.
The Ethernet PHY is a KSZ8081RNDCA. This device takes a 50MHz clock input on pin 8, which we are providing from the FPGA. It also outputs the same clock on pin 16, which is not connected on the MEGA65 (and shouldn't need to be). There is nothing there that I can see is important. The clock is required to be +/- 50ppm, but nothing more. At 50ppm, this corresponds to 1 tick of drift every 1,000,000/50 = 20,000 bits. That's a little more than 2KB, so there should never be any clock drift if our clock is accurate to that level.
The only fishy thing that I can see that I have done, is that the 50MHz clock to the Ethernet PHY goes through two BUFG clock buffers in the FPGA, instead of just one. I can't find any clear information on this, but I don't really see how it could cause excess jitter in the clock, since the purpose of BUFGs is to provide robust clock distribution. But it probably makes sense to remove it.
Well, removing the extra BUFG hasn't really helped. So I implemented a mode in the Ethernet controller where it samples the incoming signal at 200MHz, i.e., 4 samples for every di-bit that the Ethernet PHY chip sends us. What I wanted to see, is whether the received signals have errors for a whole bit (indicating that we are correctly receiving an incorrect signal from the Ethernet PHY), or if it is just showing jitter around the edges of the groups of 4 samples (in which case we would be incorrectly receiving a correct signal from the Ethernet PHY).
I am seeing a bit of both, but the overwhelming failure mode is that there are whole bit errors.
I am thus beginning to wonder if the problem isn't with my Ethernet cable after all of this. It is 100mbit rated cat 5, but it is an old cable. It's also probably not particularly well shielded, and it does run past a lot of other cables. So it is possible that we are just seeing interference on the signals. This is easily tested by using a different cable.
Well, using a different cable, which is cat6, and in fact removing the switch and everything from between my laptop which is generating the packet stream, and the MEGA65 which is receiving it hasn't solved the problem. I am still seeing exactly the same kinds of errors: Mostly correctly timed incorrect di-bits, plus the occasional single or double sample glitch.
So what is the root cause of the issue here? Is it my Ethernet controller in VHDL doing something bad, or is it the Ethernet PHY? What I might do next, is test the same program on a Nexys4 board running the MEGA65 core, and see how it behaves there, on the basis that those boards should have known-good Ethernet.
The bitstream for the Nexys4 DDR board is built, and it seems to be exhibiting much the same problem, with bit errors being received. Again, they appear to be almost exclusively whole bit errors, i.e., with all 4 sub-samples returning the same incorrect value, rather than short glitches on the line.
Assuming that the Nexys4 DDR board has a problem-free Ethernet adaptor, this means that my Ethernet.vhdl and related bits must be where the problem lies. This is reassuring, because I was worried that the MEGA65 boards might have a problem with the Ethernet hardware. I think I will keep working on the Nexys board for a while, and get that rock-solid, before returning to the MEGA65 board. That way, I can be confident that what I have is correctly working, and if problems do occur on the MEGA65 R3 board, that there is something about the adaption to that that is the problem.
The big question is, what on earth is causing this corruption on what should be a good Ethernet connection? Maybe there is something in the MDIO registers for the Ethernet PHY chip that need to be set correctly. Having read through the datasheet, there doesn't seem to be anything in there that requires setting for it to work, but rather that the default settings should all be correct.
This all makes me suspect that there is still a problem with the 50MHz clock I am providing to the Ethernet PHY chip: If it has too much jitter, it could cause the kinds of problems we are seeing. Or at least that is my theory. Reading this, I found that I should probably have the BANDWIDTH setting of the clocks set to LOW, not to OPTIMIZED. So I'll synthesise with that, and see if it helps. I am a quietly optimistic that this will help, because it directly impacts on clock jitter.
If this doesn't work, there is some information about checking simultaneous switching outputs (SSO) in the FPGA, but I don't think that that is likely to affect the Ethernet PHY. Also, I'd be surprised if it affected both the Nexys4 board and the MEGA65 R3 board, as they have different FPGA parts with different SSO limits.
So let's hope that the clock bandwidth option fixes it... If it doesn't, then this suggests that setting the BANDWIDTH to HIGH may actually further reduce the output clock jitter. Nope, neither of those fixes the problem. If anything, with it set to HIGH, it might be worse.
I tried making a simple loop-back bitstream as well, which just ties the Ethernet RX and TX lines together, which this PHY supports, but that didn't seem to produce any output. I'd have to do a lot more fiddling to be able to investigate what is happening wrong there, so I will try to think about alternative approaches for the moment.
I might start by trying a different MEGA65 main board, in case it is a fault with this particular board.
So far it doesn't look like it is specific to a single board. It is all a bit of a mystery, as to what could be causing it, as the MEGA65's Ethernet port basically follows the reference design.
What I might try next is to lock the negotiation to 10mbit/sec, instead of allowing 100mbit/sec, and see if the problems go away at that speed. 10mbit Ethernet still delivers around 1MB/sec, so for an 8-bit machine, this should be fine.
The Ethernet PHY we are using supports 10 and 100 via the Reduced Media Independent Interface (RMII), a standardised interface for Ethernet PHYs. What is interesting is that the timing and behaviour for 100 fast Ethernet is described all over the place, but I can't find any definitive documentation on using it for 10Mbit Ethernet when it is clocked at 25MHz for fast Ethernet. It looks like it is just sending or receiving one cycle in ten, which would make sense -- but it would still be nice to have it clearly defined somewhere.
(I'm also wondering if the root-cause of the problem isn't noise from the FPGA getting into the Ethernet PHY, and causing bit-errors that way. Again, dropping to 10Mbit/sec might solve that problem, but it would be good to know if it is the root-cause or not. It's the not knowing the root-cause here that is frustrating me so much.)
Anyway, back to 10Mbit Ethernet support, the test_ethernet.vhdl testbed provides a basic test of the 10Mbit mode of operation, and that seems to work correctly. So I'll test a bitstream with it, and see if I can get 10mbit mode working. In theory, it should just be writing $10 to $D6E4 to select it in the Ethernet controller, and then writing to the MIIM registers to tell any connected switch that the machine is only offering to do 10Mbit/sec. I can verify if it has connected at 10Mbit/sec by checking the lights on my switch.
To test, I am running wirekrill on the MEGA65, and then doing the following to switch to 10Mbit/sec:
1. Write $10 to $FFD36E4 to make the Ethernet controller drop to 10Mbit/sec.
2. Clear the bits in MIIM register 4 that correspond to 100Mbit mode, i.e., bits 7 (half-duplex mode) and 8 (full-duplex mode), and set the bits corresponding to 10Mbit mode (bits 6 and 5). We can do this by:
Write $04 to $FFD36E6 to select the register
Write $00 to $FFD36E8 to set upper 8 bits
Write $61 to $FFD36E7 to set the lower 8 bits
The order is important, because writing to $FFD36E7 triggers the write to the MIIM register.
Interestingly, in wirekrill, the PHY indicates that the link status flaps quite frequently, often a few times per second. I am wondering if this might not be a clue as to the root-cause. This happens less frequently with the interface set at 10Mbit, although it does still happen every few seconds.
I'm also not seeing any packets be received with it set to 10Mbit. So it is possible that I still have an error in my 10Mbit support in the Ethernet controller.
It's a week later, and I have had time and distance to think about this all more, which is usually a good thing. While trying to find the datasheet for the Ethernet chip, so that I could see if tying the ETH_RST pin instead of leaving it floating (which is supposed to be okay), I found the silicon errata document for the chip. This is basically the "hardware bug list" for a chip, and which often has work-arounds for problems. Anyway, what would you know: There is errata about packet loss and bit errors. It might not solve our problem, but its certainly worth a try.
The issue for this chip, is that it can get bit latching errors due to clocks edges being too close when using 25MHz mode (which we are using). There is a software procedure for detecting and then correcting the problem by one of several timing adjustment methods. That sounds quite promising.
In tooling up for this, I have accidentally discovered something interesting: Some bitstreams are much worse for the problem than others: 066350c doesn't show any link flapping, while the head of my Ethernet fixes branch on commit 6b5b541 flaps often multiple times per second. I'm assuming that the link flapping is related to the error rate, which I can confirm shortly.
I really want to probe the ETH_RST pin, to see if I can see any noise being picked up on that. Nope, the RST pin is sitting on a solid 3.3V -- so even though the schematic showed it to be floating, it is apparently pulled up. So that' can't be the problem. So we can exclude the reset line floating as the source of the link flapping.
Okay, this is really weird: With the Ethernet cable removed, I am still seeing link flapping. Is this really real, or is it a problem with the MDIO communications, making it think the link is flapping?
Adding some extra debugging, I can see that the MDIO interface does seem to be at least part of the problem: It is reading all sorts of crazy values, some of which look like it has read the wrong register. Part of the problem here, is probably that the MDIO link state scanning code doesn't enforce waiting for the MDIO transaction to finish before reading, because it looks for flaps during the inner packet-wait loop. Thus it might even end up triggering reads before the previous read has finished, which is likely to also cause problems. So I'll try to improve that by making it check only once per frame, and checking the state just before the read is scheduled.
I have fixed that, and now it is only reporting what look like true link status changes, with the value for MDIO register 1 (that has the status info in it), only changing the couple of bits related to link changes. But the flapping is still happening. Also, I have just noticed that the MEGA65's Ethernet port on my switch is never showing any LEDs to indicate link status. I'm not sure if that's because it hasn't sent any Ethernet frames, or whether it is because it really thinks the link is down.
If I cold reset the MEGA65 to an old bitstream, c3f0e60, from December 2021, it does cause the link LEDs on the switch to light, but for 10Mbit/sec, not 100Mbit/sec. Switching to my new bitstream, but without resetting the Ethernet, the 10Mbit/sec LED stays on the switch. Ah... It might be that the ethernet reset pin is connected, and that I am toggling it for too short a time: The datasheet requires at least 500usec.
Hmm... even with that wirekrill is still somehow leaving the Ethernet controller in a state where the LEDs on the switch don't light. If I stop the CPU, and manually reset the Ethernet controller, then it comes good, and doesn't link-flap.
Yes, it looks like 10ms isn't actually long enough. It looks like more like 100ms is required for each of those phases of the reset process. With that, the link comes up clean, and stays up. Hopefully this also fixes the RX errors, as perhaps it was some calibration thing being cut short, that can now complete properly.
This is quite encouraging. So now its back to trying to get the fetch browser to work, and also I should still make the TX loopback check that the errata document indicated. I want to do the loopback check with both the internal digital loop-back, i.e., inside the Ethernet PHY, and then also with external analog loop-back, i.e., using a short loop-back cable.
Let's start with the digital loop-back test. I'll add this as a function into wirekrill. I've implemented this so that if you press the D key, it switches to digital loop-back mode, and starts sending 50 frames per second that consist of a broadcast Ethernet frame from 01:02:03:40:50:60 with Ethernet frame type 0x1234. The frame then consists of 256 bytes from 0x00 -- 0xff. If I see one of these frames being received, I can then check the body of the frame, to check for errors... And errors I am indeed seeing, e.g.:
0xAC is read as 0xA8 in this one:

0xAC = 10101100 in binary, which corresponds to the 4 di-bits 10 10 11 00. It is read as 0xA8 = 10 10 10 00. Notice how it is just the third di-bit that is wrong, and that is a copy of the previous one. This suggests that it is likely the funny clocking issue referred to in the errata document.
You can play spot-the-error for yourself in these two frames here:

Are these errors of a similar type? First we have 01 01 01 00 becoming 01 01 01 10, so again, its a single di-bit error, but in this case, it's not a copy of the preceding or following di-bit. For the second one, we have 00 11 00 00 becoming 11 11 00 00, which is another copy of the previous di-bit (from the end of 00 11 11 11).
This all suggests that it is well worth trying their suggested fixes. They suggest 3 different ones:
1. Just reset the PHY and try again. Apparently there is some randomness in this. I don't like that idea.
2. Adjust the REFCLK pad skew, in steps of +/- 0.6ns. This sounds like a very sensible approach. This is done by adjusting bits 12--15 of register $19.
3. Adjust the drive current strength of certain signals using bits 13--15 of register $11. That seems less likely to be the root cause than option 2, but it might work for helping the non-edge fudged errors, like in the byte that went from 01 01 01 to 01 01 01 10.
Right, so let's start by adjusting the REFCLK edge. I'll make the number keys select different delays, so that I can probe it in real-time.
Hmm.. Interesting: Register $19 is not documented in the data-sheet! This is some secret-squirrel register. Same goes for $1A... I wonder what the other bits of these do.
Anyway, adjusting the REFCLK delay doesn't make any difference. Nor does repeatedly resetting the Ethernet PHY. So let's hope that the drive current strength makes a difference.
Interesting: Those bits are also not documented in the main datasheet, just being listed as "RESERVED". Am I using the wrong data-sheet, or are these all undocumented features?
Anyway, so far, none of the three methods have worked to correct the problem. I am also seeing intermittent problems reading the MDIO registers, which might mean that some of my attempts to set things up are not working, which could be muddying the tests. So I need to get to the bottom of that.
One interesting thing I have noticed once I started reporting the position of the first incorrect byte in an Ethernet frame, is that almost all of the errors are on 4 byte boundaries, e.g.:

This suggests that these errors aren't truly random, but probably doesn't help me to really track the source down. I am intrigued, however, to more thoroughly map where the errors in the frames tend to occur. Here is what the distribution of di-bit errors looks like, when collected over a bunch of frame:

The top few rows of the screens report the number of errors seen in each di-bit posititon. A full-stop means no errors were seen in that position. Each four di-bits makes a byte, and to highlight this, I have made each byte's worth of di-bits alternate between normal and reverse characters. The colours just indicate the di-bit position, within the byte, to make it easier to see where the errors tend to collect.
The most striking thing, is that the vast majority of errors happen only in the even numbered bytes! There are only 17 errors in odd-numbered bytes, compared with many hundreds. Then within the even numbered bytes, the errors are much more likely to occur in the 3rd or 4th di-bits, than the first two. So for whatever reason, 2 consecutive di-bits from each sequence of 8 di-bits are particularly error prone.
This tells us that the errors are not random. It also suggests that it isn't an overall clock skew issue. It might be a clock jitter problem, if the jitter is robustly repetitive in nature. I don't know enough about FPGA clock generators to know if that's likely or not. But even that isn't a really good explanation for what is going on, because this is all happening in the digital loopback domain. That is, it should all be happening with a common clock, if I understand the operation of this Ethernet PHY correctly. Also, the maximum jitter in the clock from the FPGA should not be more than about 0.3ns, while the 50MHz Ethernet clock has a period of 20ns.
Anyway, I have re-run the tests with different REFCLK pad delay settings and current drive settings, and there is no apparent change in the pattern.
I've also just double-checked that the problem isn't with the Ethernet RXD to clock phase when latching the received data: The default value works no differently to 2 of the other values, and as expected, the 4th possible value results in rubbish, because it moves the latch point to exactly when the data lines are changing.
I should probably check the TXD to clock phase, in case that's marginal. No real difference there, either.
So with those sanity checks, I'm back to thinking that something in the way the chip is behaving -- possibly because of clock jitter -- is at play.
This suspicion is growing, because when I use the older 066350c bitstream from June 2022, I get a quite different result, with many fewer errors. In fact, I am seeing dozens of good frames between bad frames, and the errors that do occur are clustered much more closely to the end of the frames:

The fact that there are fewer errors visible on the map is not a direct indication of the reduced error rate (that I can tell by watching the test run, which during running displays "Good loop-back frame received" and a different message when a bad one is received, as shown in some of the earlier screen-shots).
Rather, what this last screenshot is directly telling us, is that the errors are very strongly clustered to those few positions: The test aborts as soon as it tries to count a 10th error in a single position. In the previous tests, errors were being sprayed all over the place, and we thus saw very many errors before a single position had encountered 10 errors. Now we are seeing only 7 positions that suffer errors: Still clustered on the last 2 di-bits of even bytes.
What I'm not sure, is if that bitstream actually works properly for Ethernet or not, as its probably old enough the buffer rotation was still broken, and so it might be seeing the same good frames repeatedly. So I'll build a fresh bitstream, and see if the error rate changes from random synthesis effects. In the meantime, I'll also try some other bitstreams from between the two, and see how the error rate varies.
Righty-oh. The fresh bitstream has been built, and the error distribution has changed:

Notice how ther errors are still clustered in particular columns, but differently to before. This tells me that there is something in the FPGA synthesis that is variable and affecting things. At the same time, I also implemented a test frame sending function, and using tcpdump on my attached Linux machine, have confirmed that no bit errors occur in the TX direction -- this is purely an RX artefact that we need to track down.
Thinking about it, it could be that the signal path length between the RXD bits are different, i.e., that one of the two bits of the di-bit channel arrives sooner than the other one. The clustering of the errors might be a side-effect of the data that I am putting in the frames.
To try to debug this, I changed the data pattern that I am sending, which has uncovered something quite interesting, both when I try sending all zeroes and all ones. These screenshots show the contents of the received frame:


First up, we can see that some bytes are quite clearly messed up in both cases: So we are seeing low-to-high and high-to-low errors.
Second, the errors within the bytes don't look particularly random to me.
This means that the problem is most likely when we are storing or retrieving the Ethernet frames, not the actual receiving of them! Perhaps the logic that controls the chip-select lines of the Ethernet RX buffers is the problem. The way I was setting these was quite likely prone to glitching, which could cause exactly the kind of problems that we are seeing. Also, it explains the mystery of why we are seeing frames with errors, that claim to have passed the Ethernet CRC test: The frames are likely completely valid, but because we are seeing mash-ups of the contents of multiple frames, we see what look like corrupted frames.
Anyway, this is all a nice piece of progress, and I am now synthesising a bitstream that has de-glitched Ethernet RX buffer CS line selection, to see if this fixes the problem. Fingers crossed!
Meanwhile, in trying to figure this all out, I am also seeing that the reading of received Ethernet frames is several frames behind the most recently received one. This makes it tricky to verify the contents of the frames, if I want to put different content in each frame. These problems with the handling of the receive buffers I thought I had long since solved, but apparently not.
I'm now putting in a quick fix that will point the CPU to the correct Ethernet RX buffer when the queue is empty.
Looking at the code, I am also wondering if there isn't a problem with the signal path being too slow from the 50MHz Ethernet side of things to the 40.5MHz CPU clock side, when handling the Ethernet RX buffer writes. It is possible that this might be responsible for the messed up buffer contents: In this scenario, the writes would not be happening at all, or might be written to the wrong places. It would also explain the funny periodicity of the errors through the RX buffers. I'll have a think about this a bit later in the day. The correct solution might be that we have to add a small FIFO that handles the write queue to the RX buffers. Or alternatively, we might be able to have the writes done natively on the 50MHz Ethernet clock side of things: It certainly seems like that should be possible.
Taking a closer look, the writes were happening from the 50MHz side, but it was clocked by the CPU clock, and various other messed up things. This could certainly explain the general mess of results that get written into the buffers. Fixing that now, and resynthesising.
Well, that seems to have improved things, in that the fetch browser now more reliably loads pages, and much faster, too, without all the lost packets and carry-on that it was doing before. But its still playing up, and wirekrill is not behaving properly now, either. I'll have to have a poke around and figure out what is going on with those, but the weird RX errors seem to have been resolved.
I actually spent a bit of time fixing some bugs in the fetch browser, including better detection of various error conditions first. Zendar from Badgerpunch Games, the creators of the great Showdown game for the MEGA65 was online, so we made up a test H65 page with some of the content about the game, which after a bit of fiddling, we got working. I still haven't improved the md2h65 converter, so the page layout is still pretty rubbish, but the page loads, and the image looks pretty good:

First step, wirekrill is working again, showing Ethernet frames arriving. So that's good. That just leaves this ring buffer problem.
This problem should be able to be tested under simulation. I can setup just the Ethernet controller module, and feed it some frames, and then see what the CPU side will be able to read from them. What I believe is happening, is that the CPU is tracking around the ring of buffers, but in the incorrect position relative to the Ethernet side that is writing into them. Thus the CPU sees each frame only after 31 more frames have been received.
And the simulation is helping already. I can see that because we start the CPU side buffer and Ethernet controller side buffers both on 0, that the Ethernet controller writes the first frame to buffer 0, and then when the CPU accepts it, it advances to the next buffer, i.e., buffer 1, before reading.
I've synthesised this fix, but the problem is still happening. I did shrewdly also include in that synthesis run a change that will let me see the RX buffer ID that the CPU and Ethernet sides are each using at any point in time. This should hopefully let me see what is going wrong, and fix it pretty quickly.
With this, I have immediately confirmed that the CPU is trying to read from the same buffer that the Ethernet side want to write to next, i.e., its reading from the most stale buffer, and one that is in danger of being written over. This is shown in the [CPU=$xx, ETH=$xx] tags on the Ethernet Frame # lines in the screen-shot here:

So how is it getting out of whack? I am suspecting that the problem here is that a previous work-around for problems with the ring buffer is causing problems. That work-around would read lots of frames from the buffers after resetting the Ethernet controller, to make sure that there were no stale frames hanging around. However, it can cause the CPU's buffer ID to advance beyond the last true waiting frame.
Except looking closer, I think the problem is actually when the buffers all get filled up. In that case, the CPU and ETH sides will be pointing to the same buffer ID, as the Ethernet controller wants to write to the buffer that the CPU has allocated. Now when the Ethernet controller advances to the next buffer ID, it has just finished writing to the buffer ID that the CPU is currently looking at. When the CPU then asks for the next frame, it will now get the oldest frame in the ring buffer. So the problem is almost certainly related to when the ring buffer fills. Let's figure out what the correct behaviour should be, using 4 buffers to keep things simple.
Initially, we have 0 occupied buffers, and the Ethernet side is pointing to buffer 1, and the CPU to buffer 0:
CPU=0, ETH=1, buffer0=cpu, buff1=empty, buff2=empty, buff3=empty
Now if we receive an Ethernet frame, but the CPU does nothing about it, we will get:
CPU=0, ETH=2, buffer0=cpu, buff1=frame1, buff2=empty, buff3=empty
Let's continue that with 2 more frames:
CPU=0, ETH=3, buffer0=cpu, buff1=frame1, buff2=frame2, buff3=empty
CPU=0, ETH=0, buffer0=cpu, buff1=frame1, buff2=frame2, buff3=frame3
At this point, the Ethernet controller has no free buffers, and cannot receive any more frames until after the CPU has taken one of the received ones.
If the CPU takes the next frame, it will end up with:
CPU=1, ETH=0, buffer0=empty, buff1=cpu, buff2=frame2, buff3=frame3
So this should all work ok. But I think the Ethernet side might not be counting free buffers properly, or something odd might be happening when the CPU side catches up and empties the frame queue completely.
With more simulation, I can see something funny is happening when the Ethernet side buffer number reaches the maximum, and wraps back around to zero. When this happens, the CPU buffer ID is also resetting to zero, when it should be staying at the maximum buffer number. Ah, that was a new bug due to my further fixing and simplifying the buffer number management.
Okay, so now if the CPU is keeping up, it all works fine. I'll now modify the test bed so that the CPU gets slower and slower about acknowledging the frames, and see if it can still get out of sync... and it seems to work: It processes about 70 frames before it finally gets so slow, that there really is a missed Ethernet frame, which we then detect. But importantly, the buffer handling all looks solid.
I'm now synthesising that fix, so that I can test it. But in the meantime, we already have it working well enough with the last synthesis run, that I can put some focus back on the fetch browser itself.
I now want to start really forming the browser into something that is a bit more user-friendly. For starters, I want it to have some sort of welcome screen, that let's you choose what you want to do, including selecting a link from a set of favourite links (which will eventually be loadable from disk), and also presenting a much more useful interface when a page fails to load for any reason. I'd also like to have the program remember any DHCP lease it has obtained, so that it doesn't have to wait for DHCP negotiation, every time you load a page.
Caching the DHCP status is in principle quite simple:
// Do DHCP auto-configuration
dhcp_configured=fetch_shared_mem.dhcp_configured;
if (!dhcp_configured) {
printf("\nRequesting IP...\n");
dhcp_autoconfig();
while(!dhcp_configured) {
task_periodic();
// Let the mouse move around
update_mouse_position();
}
printf("My IP is %d.%d.%d.%d\n",
ip_local.b[0],ip_local.b[1],ip_local.b[2],ip_local.b[3]);
// Store DHCP lease information for later recall
fetch_shared_mem.dhcp_configured=1;
fetch_shared_mem.dhcp_dnsip=ip_dnsserver;
fetch_shared_mem.dhcp_netmask=ip_mask;
fetch_shared_mem.dhcp_gatewayip=ip_gate;
} else {
// Restore DHCP lease configuration
ip_dnsserver=fetch_shared_mem.dhcp_dnsip;
ip_mask=fetch_shared_mem.dhcp_netmask;
ip_gate=fetch_shared_mem.dhcp_gatewayip;
// Re-constitute ip_broadcast from IP address and mask
for(i=0;i<4;i++) ip_broadcast.b[i]=(0xff&(0xff^ip_mask.b[i]))|ip_local.b[i];
}
}
And it seems to work somewhat. But for some reason when I try to load a page using the cached DHCP lease, something writes over something else and sends the program off into la-la land. It seems to get as far as doing the DNS resolution, but no further. I'm not sure if the DNS resolution really is completing, though, as the URL I am using has an IP address, rather than a hostname.
Adding some more debug output, it claims to make the connection, but I don't see any evidence of the HTTP request being made, and eventually it times out.
So time for even more debug output! Which has yielded us a good clue: The gateway but not local IP address is being saved and restored:
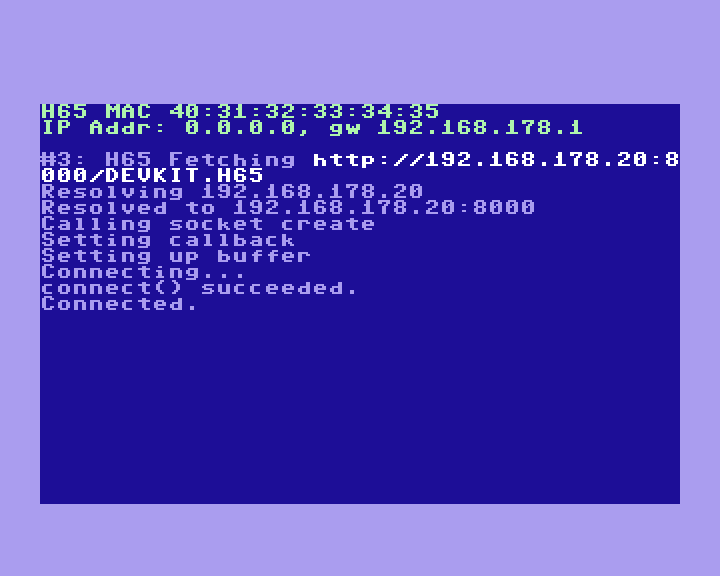
Which let met realise that I was saving and restoring all the other fields, except for the IP address. Oh dear. At least it's easily fixed. And with that done, I can now do DHCP negotiation once, and then load multiple pages after that. Nice.
It is having some trouble following relative links, however. It says something like "Parsing '/INDEX.H65'", and then gets stuck in a tight infinite loop. What makes this a little tricky to debug, is figuring out exactly where this code corresponds to. This is the bit where it is stuck in $5722:
,00005700 AD 40 B7 LDA $B740
,00005703 AE 41 B7 LDX $B741
,00005706 20 78 2E JSR $2E78
,00005709 AD 25 A5 LDA $A525
,0000570C C9 FF CMP #$FF
,0000570E F0 15 BEQ $5725
,00005710 A9 48 LDA #$48
,00005712 A2 A2 LDX #$A2
,00005714 20 46 9B JSR $9B46
,00005717 AD 25 A5 LDA $A525
,0000571A 20 44 9B JSR $9B44
,0000571D A0 04 LDY #$04
,0000571F 20 F4 9A JSR $9AF4
,00005722 4C 22 57 JMP $5722
Hmm... Except that when I try it again now, it works -- subject to the problems caused by the remaining Ethernet RX buffer stuff, that I am still waiting to synthesise correctly (it's failed twice in a strange way).
Anyway, that suggests that it is probably okay, at least until I confirm it after fixing the RX buffer stuff, which will make page loading much faster, because I won't be dependent on the number of random packets on my LAN for things to get responses.
So I think I will work more on the launch screen and related user comfort stuff for a bit. This will still look pretty ugly initially, but it will at least provide a sensible starting point. I would love to have some folks help me make it look prettier.
But here's our starting point:

The next step is to add mouse support, so that mousing over an option highlights it, and clicking on it triggers the action. This was fairly easy once I got the geometry conversion from mouse position to item right:
update_mouse_position(0);
mouse_update_position(&mx,&my);
if (my>0x70) {
// Work out which choice row is currently selected
// mouse res is in 320x200, so each 2 rows of text is 8 pixels
choice=(my-0x78)>>3;
for(i=20;i<25;i+=2) {
if (i==(18+choice*2)) lfill(0xff80000+i*80,0x2d,80);
else lfill(0xff80000+i*80,0x0d,80);
}
}
// Check for mouse click on a choice
// (Implement by cancelling a mouse-indicated choice, if the mouse isn't being clicked)
if (!mouse_clicked()) choice=0;
// Scan keyboard for choices also
switch(PEEK(0xD610)) {
case 0x47: case 0x67: choice=1; break;
case 0x31: choice=2; break;
case 0x32: choice=3; break;
}
// Act on user input
switch(choice)
{
case 1:
// Ask user to choose URL from history, or type one in
fetch_shared_mem.job_id++;
fetch_shared_mem.state=FETCH_SELECTURL;
mega65_dos_exechelper("FETCHERR.M65");
break;
case 2: fetch_page("192.168.178.20",8000,"/index.h65"); break;
case 3: fetch_page("192.168.178.20",8000,"/showdown65.h65"); break;
}
}
This makes it nice and easy to have both keyboard and mouse input.
Next I improved the video mode switching stuff when page loads happen, so that there isn't visible glitching. I also checked our BBS client, now that the network stuff is working better, and that is also a million times nicer to use now. I'll do a separate post on that.
But let's close out this post with the video from the live-stream I did yesterday demonstrating the work so-far. Note that while the BBS client is currently in 40x25 mode, there is no reason why it can't operate in 80x25 or 80x50 mode.
great stuff! so cool to have an ethernet connection to play with on a C65 err MEGA65🍻❤️
ReplyDeleteThat was a long one! Great progress.
ReplyDeletePlease say "IP Address" instead of just "IP". You're not requesting a new Internet Protocol from DHCP, right? :)
ReplyDelete